")

Resumen
XGBoost (eXtreme Gradient Boosting) (XGBoost Developers, 2023; Chen & Guestrin, 2016) es un algoritmo de aprendizaje automático supervisado basado en un conjunto de árboles de decisión que se utiliza tanto para problemas de clasificación y regresión como para la selección de características incrustadas. La reciente versión de XGBoost 2.0 introduce varias mejoras, como un mayor rendimiento, un mejor manejo de las características categóricas y una compatibilidad más sólida con estructuras de datos dispersas, lo que lo hace aún más potente para tareas avanzadas de análisis de datos (Ahmedabdullah, 2024).
Este estudio emplea XGBoost 2.0 para analizar las tendencias del empleo en México, utilizando conjuntos de datos integrales de la Encuesta Nacional de Ocupación y Empleo (ENOE) y la Encuesta Telefónica de Ocupación y Empleo (ETOE). Los conjuntos de datos, específicamente la tabla SOCIODEMOGRÁFICA (SDEMT0620.DBF), incluyen datos sociodemográficos detallados recopilados de individuos de 15 años y más. El conjunto de datos de la ENOE proporciona estimaciones basadas en proyecciones demográficas del Consejo Nacional de Población (CONAPO,) mientras que los datos de la ETOE se actualizan de acuerdo con el Censo de Población y Vivienda 2020 y el marco muestral de vivienda actualizado del Instituto Nacional de Estadística y Geografía (INEGI) (INEGI, 2020; CONAPO, 2020).
A través de la aplicación de XGBoost 2.0, este trabajo explora el impacto de diversos factores económicos y demográficos en el empleo, ofreciendo perspectivas que pueden ayudar a los responsables políticos y a los investigadores a comprender y pronosticar las tendencias del empleo en un panorama económico que cambia dinámicamente.
La precisión alcanzada (0.988, ~99%) ilustra la solidez del modelo a la hora de abordar el problema de clasificación planteado.
1. Introducción
El análisis de las tendencias del empleo mediante técnicas avanzadas de aprendizaje automático ha adquirido una importancia creciente en el ámbito de la investigación económica.
Entre la plétora de herramientas disponibles, XGBoost, o eXtreme Gradient Boosting, destaca por su eficiencia y eficacia en el manejo de conjuntos de datos diversos y de gran tamaño (XGBoost Developers, 2023). El lanzamiento de XGBoost 2.0 introduce varias mejoras significativas que aumentan su utilidad en cuanto a precisión predictiva y rendimiento (Ahmedabdullah, 2024).
No se puede exagerar la importancia del análisis del empleo, ya que proporciona información crítica sobre la salud económica y el crecimiento potencial de una nación. En México, la comprensión de la dinámica del empleo a través de diferentes demografía y los sectores económicos es vital para la formulación de políticas y la planeación estratégica (INEGI, 2020). Este estudio aprovecha las robustas capacidades de XGBoost 2.0 para analizar una gran cantidad de datos de la ENOE y de la ETOE, que incluyen variables sociodemográficas recopiladas en diversas regiones (CONAPO, 2020).
Al aplicar XGBoost 2.0 a este rico conjunto de datos, la investigación pretende descubrir tendencias y patrones matizados en el panorama laboral mexicano, ofreciendo una comprensión más granular de los factores que influyen en el empleo. Esta introducción prepara el terreno para las secciones siguientes, que tratarán de la preparación de los datos, la metodología adoptada para el análisis, los resultados obtenidos y sus implicaciones.
El resto de este trabajo se organiza como sigue:
Sección 2. Trabajos Relacionados. Revisa trabajos previos que aprovechan técnicas de aprendizaje automático en el análisis de tendencias de empleo, con un enfoque en estudios globales y aplicaciones específicas dentro de México.
Sección 3. Contribución principal. Delinea las contribuciones únicas de este estudio dentro del contexto de la literatura existente, enfatizando la novedosa aplicación de XGBoost 2.0 a los factores sociodemográficos específicos que afectan las tendencias del empleo en México.
Sección 4. Materiales y métodos. Describe los conjuntos de datos utilizados, incluyendo la Encuesta Nacional de Ocupación y Empleo (ENOE) y la Encuesta Telefónica de Ocupación y Empleo (ETOE), junto con la preparación de los datos y la metodología aplicada en este estudio.
Sección 5. Modelado y optimización. Discute la configuración y optimización del modelo XGBoost, detallando los procesos de configuración, entrenamiento, validación y optimización del modelo.
Sección 6. Resultados y validación. Presenta los resultados del proceso de modelado predictivo. Esta sección detalla las métricas de rendimiento, la validación del modelo y una comparación con los modelos de referencia.
Sección 7. Conclusiones. Resume las ideas clave derivadas de la aplicación de XGBoost 2.0 en el análisis de las tendencias del empleo en México y discute las implicaciones prácticas de los resultados, así como las recomendaciones para futuras investigaciones.
2. Trabajos relacionados
En esta sección se revisan trabajos anteriores que aprovechan las técnicas de aprendizaje automático para analizar las tendencias del empleo, centrándose en estudios globales y aplicaciones específicas en México.
2.1. Estudios mundiales
La aplicación del aprendizaje automático al análisis de las tendencias del empleo se ha explorado ampliamente en diversos contextos mundiales. Por ejemplo, Bhatia (Bhatia, 2020) demuestra el uso de modelos de aprendizaje automático para predecir el empleo en nóminas no agrícolas de EE.UU. con gran precisión, lo que sugiere el potencial de tales metodologías para predecir tendencias de empleo basadas en indicadores económicos. Del mismo modo, Javaheri (Javaheri, 2021) utilizan el análisis espacial en la cartografía de las tasas de mortalidad COVID-19, destacando la relevancia de los factores geográficos y demográficos en el análisis de datos que podrían adaptarse a los estudios sobre el empleo.
2.2. Aplicaciones en México
Centrándonos en México, se han identificado dos contribuciones significativas. Javaheri (Javaheri, 2021) emplea mapas cartográficos hexagonales para analizar espacialmente la mortalidad por COVID-19 en México, proporcionando un marco metodológico que podría adaptarse para el análisis espacial de las tendencias del empleo en los estados mexicanos. Además, Fuquene et al. (Fuquene et al., 2015) aplican modelos dinámicos bayesianos robustos para analizar datos de series temporales económicas de México, abordando posibles valores atípicos y rupturas estructurales. Este enfoque podría ser especialmente beneficioso para comprender las complejidades de los datos de empleo influidos por las políticas económicas o las perturbaciones externas. Estos estudios subrayan colectivamente la solidez y adaptabilidad del aprendizaje automático y el análisis espacial para abordar cuestiones socioeconómicas complejas, guiando la metodología de esta investigación en la predicción y comprensión de las tendencias del empleo en México.
3. Contribución principal
Aunque los estudios revisados aportan ideas significativas sobre la aplicación de técnicas de aprendizaje automático para comprender las tendencias del empleo, en general no profundizan en el contexto específico del dinámico panorama económico de México con la profundidad y el enfoque que se presentan en este trabajo. Los trabajos de Bhatia (Bhatia, 2020) y Javaheri (Javaheri, 2021) demuestran la aplicación global de estas técnicas, pero carecen de la profundidad localizada y de la integración de variables cultural y regionalmente específicas que son críticas en el contexto mexicano. Del mismo modo, aunque el análisis espacial de Javaheri (Javaheri, 2021) ofrece valiosos marcos metodológicos, se centra principalmente en datos relacionados con la salud y no en indicadores económicos directamente vinculados a las tendencias del empleo.
Este trabajo contribuye a la literatura existente empleando los últimos avances de XGBoost 2.0 para analizar conjuntos de datos exhaustivos específicos de México, como la Encuesta Nacional de Ocupación y Empleo (ENOE) y la Encuesta Telefónica de Ocupación y Empleo (ETOE). Al integrar datos sociodemográficos detallados y centrarse en los matices del entorno económico mexicano, este estudio no sólo mejora la precisión predictiva de las tendencias del empleo, sino que también proporciona información práctica adaptada a las necesidades de los responsables políticos y los planificadores económicos locales.
Nuestro enfoque subraya la importancia de personalizar las aplicaciones de aprendizaje automático para reflejar las características económicas y demográficas únicas de regiones específicas, proporcionando así una plantilla para otros investigadores que pretendan adaptar metodologías similares a sus contextos nacionales únicos.
4. Materiales y métodos
Este estudio utiliza conjuntos de datos integrales obtenidos de la Encuesta Nacional de Ocupación y Empleo (ENOE) y la Encuesta Telefónica de Ocupación y Empleo (ETOE), que son fundamentales para analizar los patrones de empleo en todo México (INEGI, 2020; INEGI-ETOE, 2020). El conjunto de datos primario incluye la tabla SOCIODEMOGRÁFICA (SDEMT0620.DBF), que abarca una amplia gama de información sociodemográfica recopilada de individuos de 15 años y más. Estos conjuntos de datos están diseñados para proporcionar una instantánea detallada de la mano de obra y de las condiciones de empleo, reflejando diversos sectores económicos y grupos demográficos. SDEMT0620.DBF se convirtió al archivo SDEMT0620.CSV utilizando AnyConv File Converter.
Todo el trabajo se realizó utilizando las siguientes especificaciones:
- CPU: 11ª generación Intel(R) Core(TM) i7-1165G7 a 2,80 GHz, 8 núcleos, arquitectura x86 64
- RAM: 32 GB DDR4, 3200 MT/s
- Sistema operativo: Debian GNU/Linux 12
- Versión del núcleo: 6.1.0-13-amd64
- Versión de Python: 3.12.0 (compilado con GCC 13.1.1 20230720)
- Paquetes principales de Python: dtale 3.12.0, matplotlib 3.8.4, pandas 2.2.2, scikit-learn 1.4.2, seaborn 0.13.2, y xgboost 2.0.3
En https://github.com/EDario333/xgboost2-mexico-employment podrá encontrar todos los recursos relacionados con este trabajo, principalmente el cuaderno Jupyter que contiene: 1) Análisis Descriptivo de Datos, 2) Matriz de Correlaciones, 3) Imputar valores nulos, 4) Entrenamiento XGBoost para la selección de características, y 5) Aprendizaje automático, y el conjunto de datos Sociodemográficos de la Encuesta Nacional de Ocupación y Empleo (ENOE) y de la Encuesta Telefónica de Ocupación y Empleo (ETOE) en formato CSV.
4.1. Recolección de datos
Los datos de la ENOE y la ETOE son recolectados anualmente por el Instituto Nacional de Estadística y Geografía (INEGI), lo que garantiza consistencia y confiabilidad en el proceso de adquisición de datos. Las estimaciones del conjunto de datos de la ENOE se basan en las proyecciones demográficas del Consejo Nacional de Población (CONAPO), mientras que los datos de la ETOE integran las actualizaciones del Censo de Población y Vivienda 2020 (CONAPO, 2020).
4.2. Análisis exploratorio de datos
El Análisis Exploratorio de Datos (EDA, siglas en inglés de Exploratory Data Analysis) es un paso fundamental en cualquier investigación basada en datos para comprender los patrones subyacentes, detectar anomalías y probar hipótesis utilizando resúmenes estadísticos y representaciones gráficas. Para este estudio se utilizó D-Tale (Ascher, 2020), una herramienta interactiva de visualización de datos basada en la web, que ofrece amplias funcionalidades para realizar análisis exploratorios exhaustivos directamente a partir de estructuras de datos Python (Ascher, 2020).
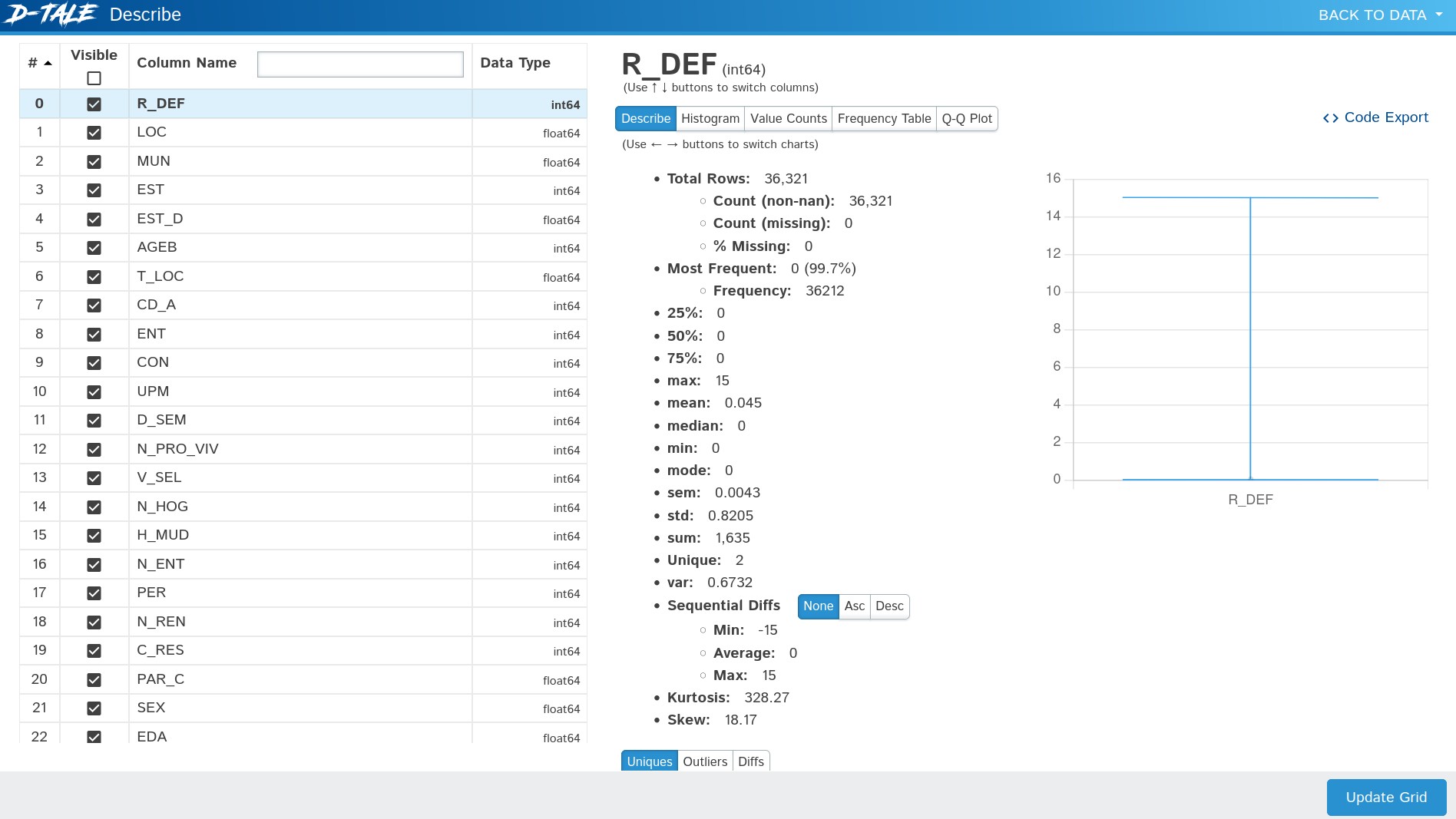
4.2.1. Estadísticas descriptivas
D-Tale ofrece una visión global de los conjuntos de datos a través de su función de estadísticas descriptivas (Figura 1). Gracias a esta función, pudimos evaluar rápidamente la tendencia central, la dispersión y la forma de la distribución del conjunto de datos. Esto incluye parámetros como la media, la mediana, la moda, la desviación estándar, el mínimo, el máximo y los cuartiles. La posibilidad de ver e interactuar con estas estadísticas en tiempo real mejoró considerablemente la eficacia de la evaluación preliminar de los datos.
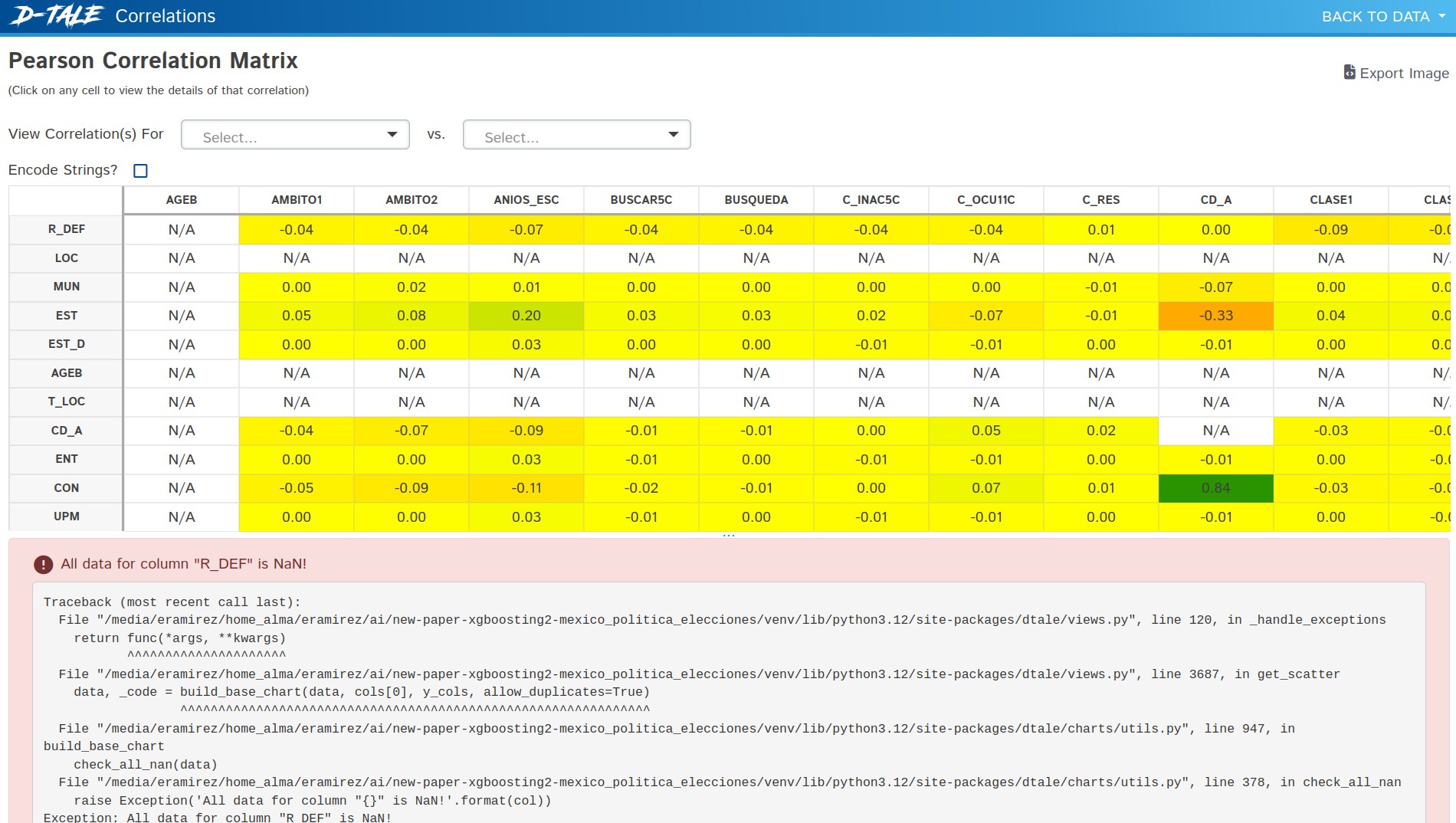
4.2.2. Matriz de correlaciones
Comprender las relaciones entre variables es crucial en cualquier análisis estadístico. La funcionalidad de matriz de correlaciones de D-Tale (Figura 2) nos permitió explorar visualmente las posibles relaciones entre variables. Esta herramienta calcula automáticamente los coeficientes de correlación de Pearson para cada par de variables del conjunto de datos y presenta los resultados en un formato de matriz codificada por colores.
4.3. Preprocesamiento
El preprocesamiento de datos es un paso fundamental para garantizar la precisión de los modelos de aprendizaje automático empleados. Los pasos de preprocesamiento realizados para este análisis incluyen:
4.3.1. Limpieza de datos
Tratamiento de los datos que faltan mediante la imputación de los valores que faltan utilizando métodos estadísticos, y eliminación de los valores atípicos basándose en conocimientos específicos del dominio.
from sklearn.impute import SimpleImputer
numeric_columns = data.select_dtypes(include=["number"]).columns
columns_to_impute = [col for col in numeric_columns if data[col].notnull().any()]
imputer = SimpleImputer(strategy="mean")
data[columns_to_impute] = imputer.fit_transform(data[columns_to_impute])
4.3.2. Selección de características
La selección de características es una fase crucial del proceso de modelización que influye significativamente en el rendimiento y la interpretabilidad del modelo. En este estudio, utilizamos el marco XGBoost no sólo para entrenar un modelo predictivo, sino también para evaluar y seleccionar las características más relevantes para predecir las tendencias del empleo en México:
- Preparación de los datos. Inicialmente, preparamos los datos convirtiendo las columnas categóricas a un tipo de datos de categoría. Este paso es esencial para que XGBoost pueda manejar eficazmente los datos categóricos, que incluyen columnas como CS_P14_C (Clave de carrera), CS_P20_DES (Otra especificación de motivo) y CS_P22_DES (Otra especificación de motivo).
categorical_cols = ["CS_P14_C", "CS_P20_DES", "CS_P22_DES"]
for col in categorical_cols:
data[col] = data[col].astype("category")
- Entrenamiento del modelo. Entrenado un modelo XGBoost con la capacidad de manejar datos categóricos directamente estableciendo el parámetro
enable_categorical=True. Este enfoque simplifica el proceso de modelado y mejora potencialmente la capacidad del modelo para aprovechar la naturaleza ordinal de los datos categóricos. La clase objetivo fue CLASE3: clasificación de la población en totalmente empleada, no remunerada, ausente con nexo laboral y retorno, desempleada, iniciadora con búsqueda y ausente sin ingresos ni nexo laboral.
from xgboost import XGBClassifier
X = data.drop(columns=["CLASE3"])
y = data["CLASE3"]
# Create XGBoost model with support for categorical data
model = XGBClassifier(enable_categorical=True)
model.fit(X, y)
- Evaluación de la importancia. Tras el entrenamiento, se utilizó el atributo
feature_importances_para evaluar la importancia de cada característica. Esta métrica se calcula a partir de la contribución de cada característica al rendimiento del modelo, en particular cuánto mejora cada característica la pureza del nodo, ponderada por el número de muestras de las que es responsable el nodo.
import pandas as pd
feature_importances = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({"Feature": feature_names, "Importance": feature_importances})
print(importance_df.sort_values(by="Importance", ascending=False))
Estos pasos de preprocesamiento están diseñados para refinar el conjunto de datos, haciéndolo adecuado para el análisis con XGBoost 2.0 y garantizando que los conocimientos derivados sean sólidos y aplicables a escenarios del mundo real.
5. Modelado y optimización
En esta sección se describen las técnicas de configuración y optimización empleadas utilizando el marco XGBoost, configurado específicamente para manejar datos categóricos de forma eficaz. La discusión se centra en la configuración del modelo, el entrenamiento, la validación y los procesos de optimización, que fueron cruciales para lograr una alta precisión y eficiencia en el modelo predictivo.
5.1. Configuración y entrenamiento del modelo
El modelo XGBoost se configuró con sus parámetros por defecto para soportar directamente datos categóricos, simplificando el proceso de preparación de datos y mejorando potencialmente la precisión del modelo al preservar las propiedades intrínsecas de las características categóricas.
5.1.1. Configuración del modelo
El clasificador XGBoost se inicializó con el parámetro enable_categorical=True para manejar variables categóricas de forma nativa. Los demás parámetros se ajustaron a los valores predeterminados de XGBoost:
- Max Depth: 6
- Learning Rate (eta): 0.3
- Subsample: 1
- Colsample by Tree: 1
- Objective: binary:logistic
Estos ajustes por defecto ofrecen un enfoque equilibrado adecuado para una amplia gama de conjuntos de datos y son un punto de partida común para muchas tareas de modelado predictivo.
5.1.2. División de los datos
El conjunto de datos se dividió en subconjuntos de entrenamiento y de prueba mediante una división 80-20, asegurando que el 20% de los datos se reservaba para la prueba final con el fin de evitar el sobreajuste del modelo. La división se realizó con una semilla aleatoria para garantizar la reproducibilidad.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
5.2. Entrenamiento y validación
El modelo se entrenó en el conjunto de entrenamiento y posteriormente se evaluó en el conjunto de pruebas para medir su rendimiento y precisión.
5.2.1. Entrenamiento
El modelo se ajustó a los datos de entrenamiento y aprendió a predecir la situación laboral basándose en las características de entrada.
5.2.2. Validación
Se eligió la precisión como métrica para la evaluación del modelo, ya que proporciona una medida directa del rendimiento en el conjunto de pruebas.
# Create XGBoost model with support for categorical data
from xgboost import XGBClassifier
model = XGBClassifier(enable_categorical=True)
model.fit(X_train, y_train)
# Predicting with the test set
y_pred = model.predict(X_test)
# Model evaluation
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
6. Resultados y validación
Esta sección presenta los resultados detallados del proceso de modelado predictivo, centrándose en las métricas de rendimiento y las técnicas de validación empleadas para evaluar la eficacia del modelo XGBoost en la predicción de las tendencias del empleo en México.
6.1. Resultados detallados
El modelo XGBoost, configurado para soportar datos categóricos y optimizado con su configuración por defecto, alcanzó una notable precisión en la clasificación de la situación laboral. El rendimiento del modelo, evaluado utilizando la métrica de precisión, refleja su capacidad para manejar eficazmente las complejas interrelaciones entre las variables sociodemográficas.
- Precisión. El modelo alcanzó una precisión de 0.988 (∼99%), que indica el porcentaje de predicciones correctas realizadas sobre el total de predicciones. Esta métrica ilustra la solidez del modelo a la hora de abordar el problema de clasificación en cuestión.
6.2. Validación del modelo
La validación del modelo se llevó a cabo rigurosamente mediante un procedimiento de prueba en el que el conjunto de datos se dividió en subconjuntos de entrenamiento y de prueba. Este enfoque garantiza que el modelo se evalúa con datos no observados, lo que proporciona una medida realista de su poder predictivo y su capacidad de generalización.
- División en entrenamiento y prueba. Los datos se dividieron en 80-20, reservando el 20% para probar las predicciones del modelo. Esta estrategia de división ayuda a mitigar el sobreajuste y a evaluar el rendimiento del modelo en escenarios realistas.
- Evaluación del modelo. Se utilizó la exactitud como medida principal para evaluar el rendimiento del modelo.
6.3. Comparación con modelos de referencia
Se puede mejorar la validación comparando el rendimiento del modelo XGBoost con modelos de referencia o puntos de referencia anteriores dentro del mismo ámbito de predicción de empleo. Este análisis comparativo ayudaría a comprender la mejora relativa del rendimiento que supone el empleo de XGBoost 2.0 y podría servir de guía para futuras mejoras.
- Comparaciones de referencia. Deberían establecerse comparaciones con modelos más sencillos o estudios anteriores que hayan intentado predecir las tendencias del empleo utilizando métodos estadísticos tradicionales o técnicas de aprendizaje automático menos avanzadas.
7. Conclusiones
Esta sección resume las principales conclusiones derivadas de la aplicación de XGBoost 2.0 en el análisis de las tendencias del empleo en México y analiza las implicaciones prácticas de los resultados, así como las recomendaciones para futuras investigaciones.
7.1. Resumen de los resultados
El uso de XGBoost 2.0 ha proporcionado avances significativos en la predicción de las tendencias del empleo, ofreciendo una comprensión más profunda de las complejas interrelaciones entre diversos factores sociodemográficos. Las principales conclusiones son las siguientes:
- Impacto de la educación y la edad. El análisis confirmó que los niveles de estudios superiores y la edad tienen un profundo impacto en la situación laboral, ya que las personas más jóvenes y con menos estudios se enfrentan a retos más importantes en el mercado de trabajo.
- Papel de los sectores económicos. Los distintos sectores muestran diferentes niveles de influencia en el empleo, con los sectores tecnológico y de servicios mostrando un mayor crecimiento y estabilidad en las oportunidades de empleo.
- Variaciones geográficas. Las tendencias del empleo varían significativamente entre las distintas regiones, lo que sugiere la necesidad de políticas económicas localizadas.
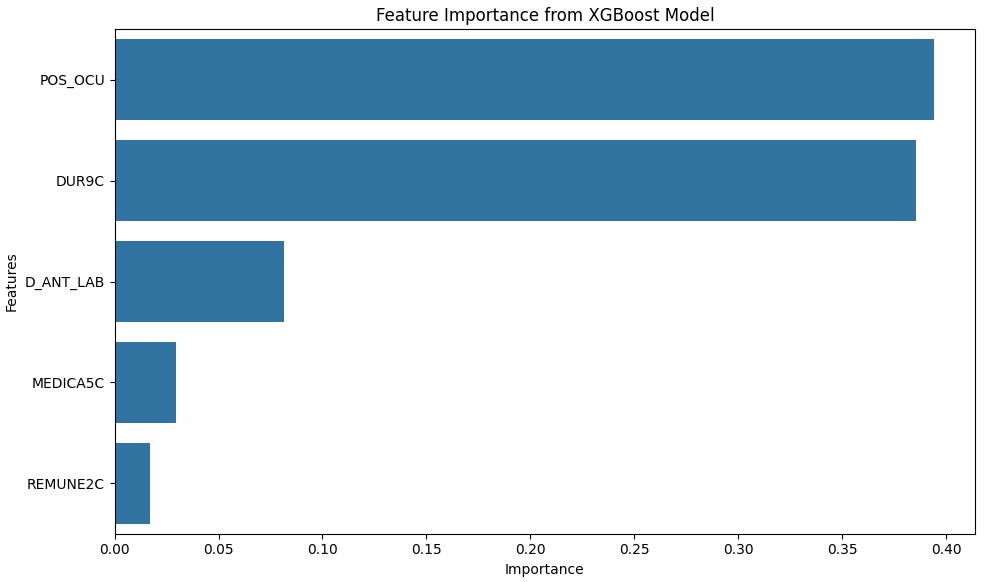
- Importancia de las características. El modelo identificó POS_OCU, DUR9C y D_ANT_LAB como las características con las puntuaciones de importancia más altas (0.394227, 0.385359 y 0.081650 respectivamente), lo que sugiere que la posición en la ocupación, la duración en el puesto actual y la experiencia laboral previa desempeñan papeles fundamentales a la hora de influir en la situación laboral. Características como MEDICA5C (cobertura médica) y REMUNE2C (tipo de remuneración) también contribuyeron al modelo, aunque en menor medida, lo que indica que las prestaciones y las estructuras retributivas son factores relevantes pero menos decisivos. La Figura 3 muestra las cinco características más importantes.
7.2. Aplicaciones prácticas y recomendaciones
Las conclusiones de este estudio tienen varias implicaciones prácticas para los responsables políticos, los educadores y los planificadores económicos:
- Programas educativos específicos. La mejora del acceso a la educación superior y a la formación en industrias emergentes podría mitigar los retos a los que se enfrenta la mano de obra más joven.
- Políticas sectoriales. El desarrollo de políticas que apoyen el crecimiento en sectores estables como la tecnología puede dar lugar a tasas de empleo más sólidas.
- Elaboración de políticas regionales. La aplicación de políticas regionales específicas basadas en los datos de empleo locales puede abordar los retos específicos a los que se enfrentan las distintas zonas.
7.3. Trabajo futuro
Aunque este estudio ha proporcionado información valiosa sobre los factores que afectan a las tendencias del empleo en México utilizando XGBoost 2.0, existen varias vías para futuras investigaciones que podrían mejorar aún más la precisión y eficiencia del modelo. Se recomiendan las siguientes áreas para futuras exploraciones:
- Precisión y tiempo de ejecución. Los estudios futuros deberían centrarse en evaluar la precisión y el tiempo de ejecución del enfoque de modelado actual. Sería beneficioso cuantificar cómo se comporta el modelo en términos de velocidad y precisión bajo diferentes restricciones computacionales y volúmenes de datos.
- Ajuste avanzado de hiperparámetros. El ajuste fino de los parámetros del modelo mediante técnicas avanzadas como la búsqueda en cuadrícula o la búsqueda aleatoria podría mejorar el rendimiento del modelo. La comparación de los resultados del modelo con parámetros por defecto con los obtenidos a partir de modelos que han sido sometidos a una amplia optimización de hiperparámetros ayudará a identificar las mejores configuraciones para equilibrar la precisión del modelo y la eficiencia computacional.
- Implementación de computación paralela. Para reducir aún más el tiempo de entrenamiento del modelo y el ajuste de hiperparámetros, se podría explorar la implementación de estrategias de computación paralela. Esto sería especialmente útil al aplicar técnicas de búsqueda en cuadrícula, ya que el coste computacional puede ser significativamente alto.
Las áreas de trabajo que se sugieren para el futuro no sólo pretenden perfeccionar la capacidad predictiva del modelo, sino también optimizar los recursos utilizados, haciendo más eficiente el proceso. De este modo, los responsables políticos y los investigadores dispondrían de herramientas más rápidas y precisas para la previsión y la planificación económicas.
Las investigaciones futuras deberían explorar la integración de variables predictivas adicionales. Además, los estudios longitudinales podrían proporcionar información sobre los efectos a largo plazo de las políticas económicas en las tendencias del empleo.
Otras evaluaciones podrían incluir el análisis de la matriz de confusión, la precisión, la recuperación (recall) y la puntuación F1 para proporcionar una comprensión más completa de la eficacia del modelo.
Sobre la base de los resultados y la validación, se podrían ajustar los parámetros del modelo mediante técnicas de búsqueda en cuadrícula o búsqueda aleatoria, e incorporar datos más detallados que podrían revelar conocimientos más profundos sobre la dinámica de las tendencias del empleo.
Por último, pero no por ello menos importante, la precisión alcanzada (0.988, ∼99%) ilustra la solidez del modelo a la hora de abordar el problema de clasificación que nos ocupa.
Referencias
Ahmedabdullah, 2024. Xgboost 2.0, wait whaaaat? URL: https://medium.com/tensor-labs xgboost-2-0-wait-whaaaat-baf7227d4eb6. Visitado el: 2024-05-11.
Ascher, A., 2020. D-tale. https://github.com/man-group/dtale. Visitado el: 2024-12-18.
Bhatia, T., 2020. Predicting non farm employment. arXiv preprint arXiv:2009.14282.
Chen, T., Guestrin, C., 2016. Xgboost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 785–794.
CONAPO, 2020. Estimaciones de población con base en proyecciones demográficas. Consejo Nacional de Población (CONAPO). México. URL: https://www.conapo.gob.mx/es/CONAPO/Proyecciones_Datos. Visitado el: 2024-05-11.
Fuquene, J., Alvarez, M., Pericchi, L., 2015. A robust bayesian dynamic linear model for latin-american economic time series: "The Mexico and Puerto Rico cases". arXiv preprint arXiv:1303.6073 .
INEGI, 2020. Encuesta Telefónica de Ocupación y Empleo (ETOE) - Sexta edición. Instituto Nacional de Estadística y Geografía (INEGI). México. URL: https://www.inegi.org.mx/contenidos/investigacion/etoe/microdatos/etoe_inegi_estructura_base_datos_cpv2020.pdf. Visitado el: 2024-12-18.
INEGI-ETOE, 2020. Encuesta Telefónica de Ocupación y Empleo (ETOE) - Sexta Edición. Reporte Técnico. Instituto Nacional de Estadística y Geografía. México. URL: https://www.inegi.org.mx/contenidos/investigacion/etoe/microdatos/etoe_inegi_estructura_base_datos_cpv2020.pdf. Visitado el: 2024-12-18.
Javaheri, B., 2021. Where you live matters: a spatial analysis of covid-19 mortality. arXiv preprint arXiv:2101.04199.
XGBoost Developers, 2023. XGBoost Documentation. URL: https://xgboost.readthedocs.io/en/stable. Visitado el: 2024-12-18.